Intro I’m not a big gamer, but I played a lot when I was younger. Having dug out a Sega
Continue reading
The thoughts and ramblings of an Engineer
Intro I’m not a big gamer, but I played a lot when I was younger. Having dug out a Sega
Continue reading
Intro I wired my house, circa 2014, for CCTV. At the time, I didn’t have as much confidence as I
Continue reading
Intro I did a post some time back about repairing a portable air conditioner unit. They’re not very complex bits
Continue readingThis is a really peculiar error. It seems to be caused in the past few months by some sort of
Continue reading
Chest freezers are ugly beasts. If you don’t have an appropriate garage or other outbuilding then you’re stuck with keeping
Continue reading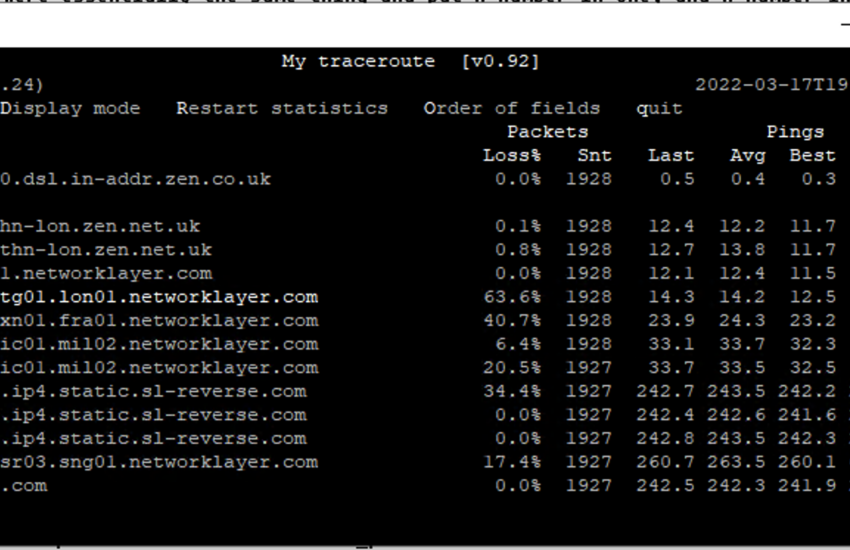
traceroute vs mtr When a packet travels across the Internet, it travels through multiple routers. The traceroute and mtr tools
Continue readingIf you add error_reporting to the end of the list of the disable_functions setting in your php.ini then Wordpress can no longer change error_reporting settings and, thus, the setting provided in your php.ini will be honoured.
Continue reading
Intro When looking for a drinks cabinet for wine and spirits, I couldn’t find anything which took my fancy. Some
Continue reading
The Problem You have a list of numbers in a table and you want to generate a new number, between
Continue readingAWS Aurora Global is, on the face of it, a decent product. Aurora is a MySQL fork with a tonne
Continue reading